Facts Vs. Dimensions Tables in a Database
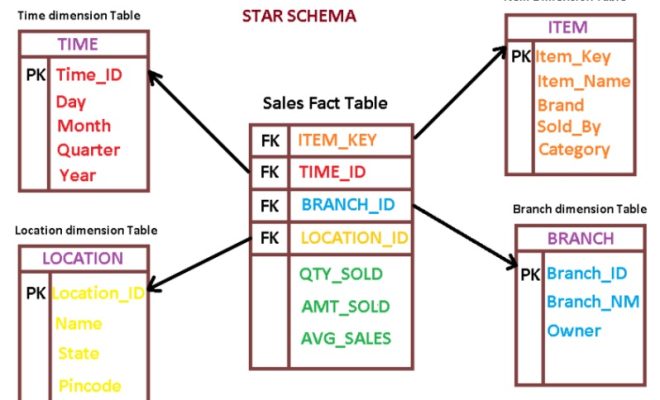
In a database, the two most common types of tables are facts and dimensions tables. Understanding the difference between these two types of tables is essential for designing an effective database schema.
Facts tables contain the measurable data in a database. They represent the numerical values, or “facts,” that are being analyzed. For example, in a sales database, the facts table might contain columns for the quantity sold, the price per unit, and the total revenue for each sale. Facts tables are often large and contain millions or even billions of rows of data.
Dimensions tables, on the other hand, contain descriptive information about the facts in the database. They are used to provide context to the data in the facts table. For example, in a sales database, the dimensions table might contain columns for the date of the sale, the salesperson who made the sale, and the product that was sold. Dimensions tables are typically smaller than facts tables and contain fewer rows of data.
One of the key benefits of using a dimensional model, which is based on facts and dimensions tables, is that it allows for flexible and efficient querying of the data. By separating the descriptive information from the numerical data, queries can be run more quickly and efficiently. This is because the database can use indexing and other optimization techniques to search the smaller dimensions tables for the desired information, rather than having to scan the entire facts table.
Another benefit of using facts and dimensions tables is that it makes the database easier to understand and maintain. By separating the data into logical groupings, it becomes easier to visualize the relationships between the data and to identify any data quality issues that may exist.
In summary, facts and dimensions tables are two essential components of a dimensional model in a database. Facts tables contain the measurable data, while dimensions tables provide descriptive information about that data. By separating the data in this way, it becomes easier to query and maintain the database, and to gain insights from the data that might not be apparent otherwise.